

The AI Factory Engine
Run Your GPU Fleet. Govern Your Tokens.
Deliver AI at Scale.
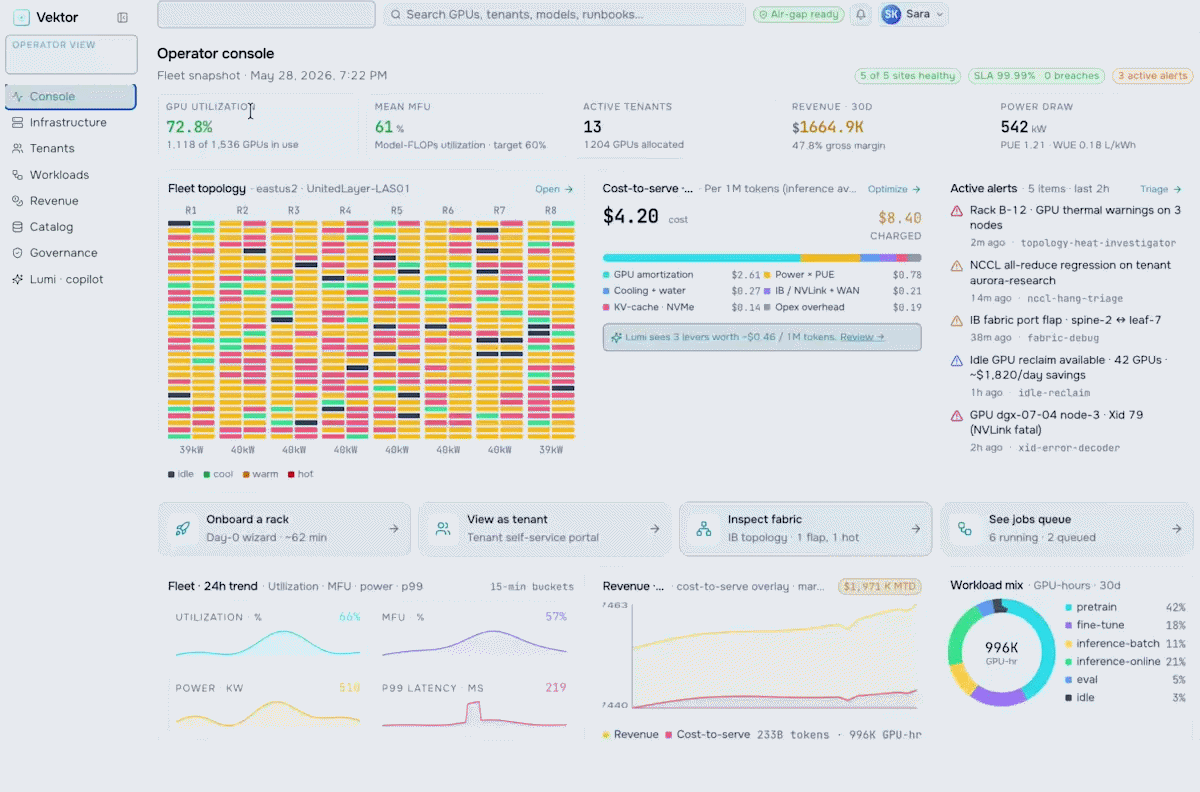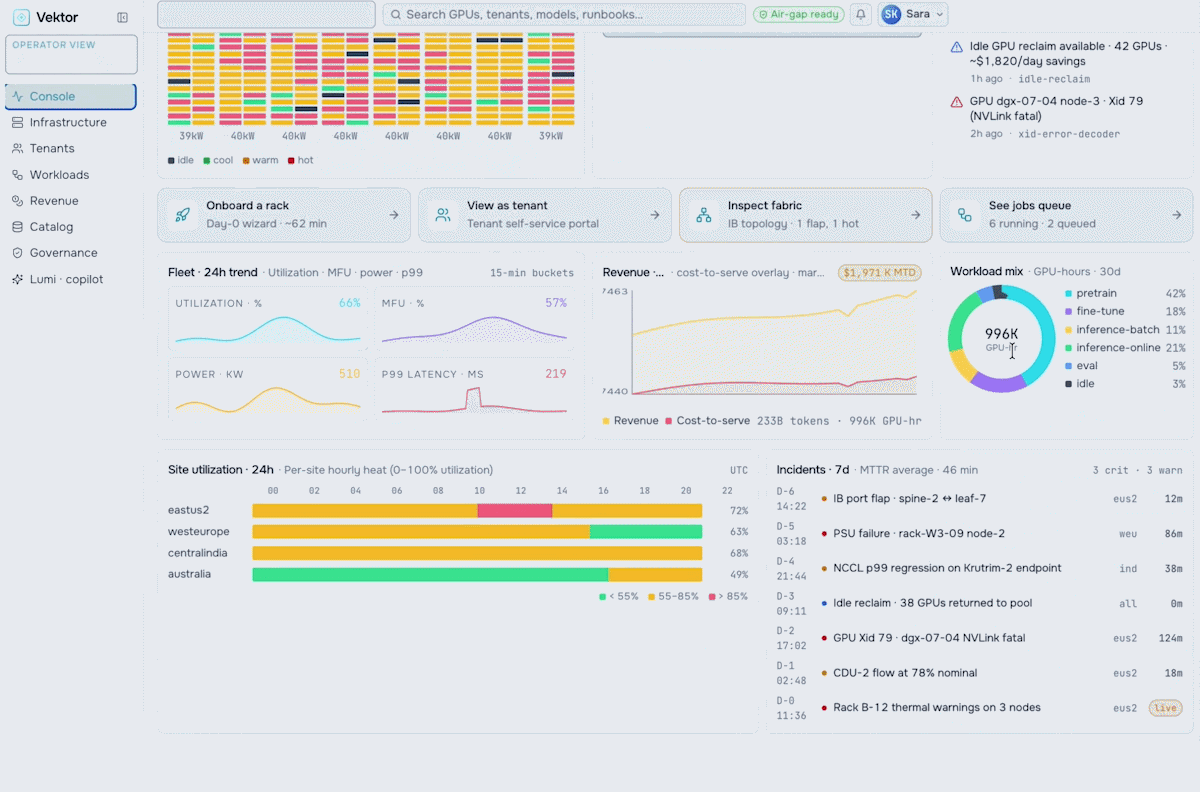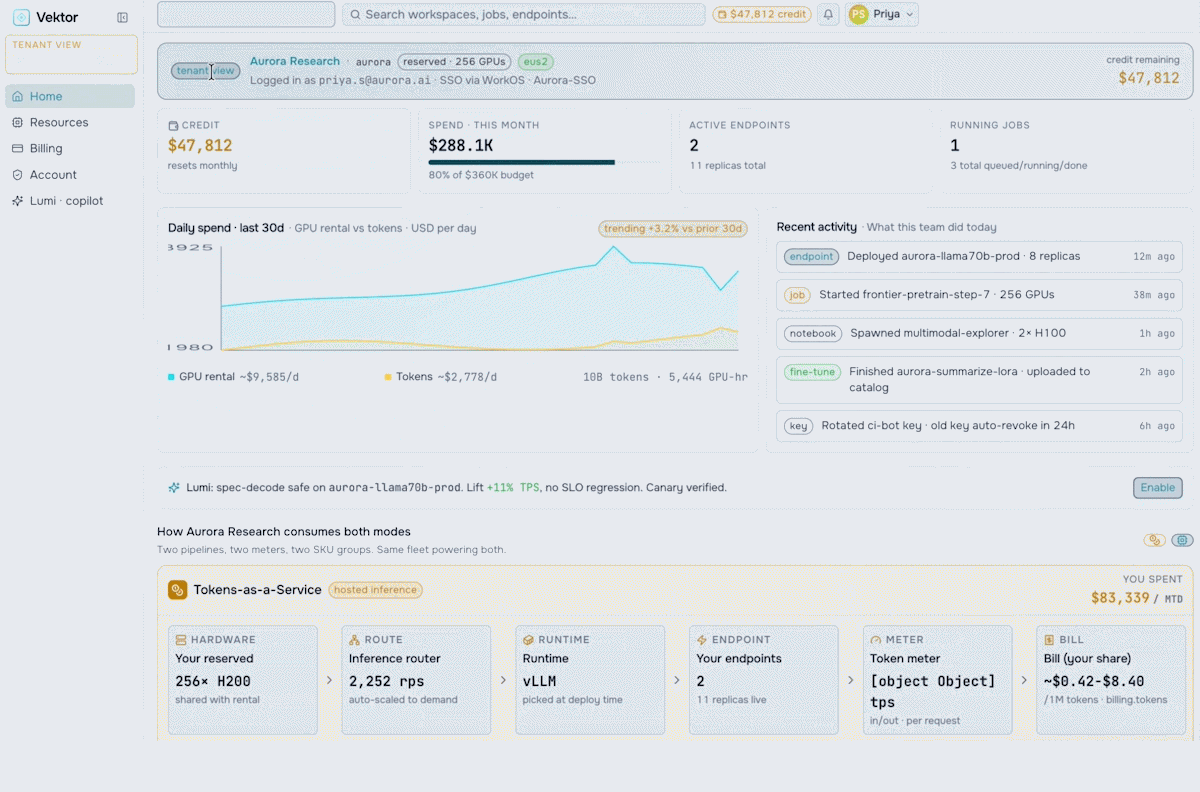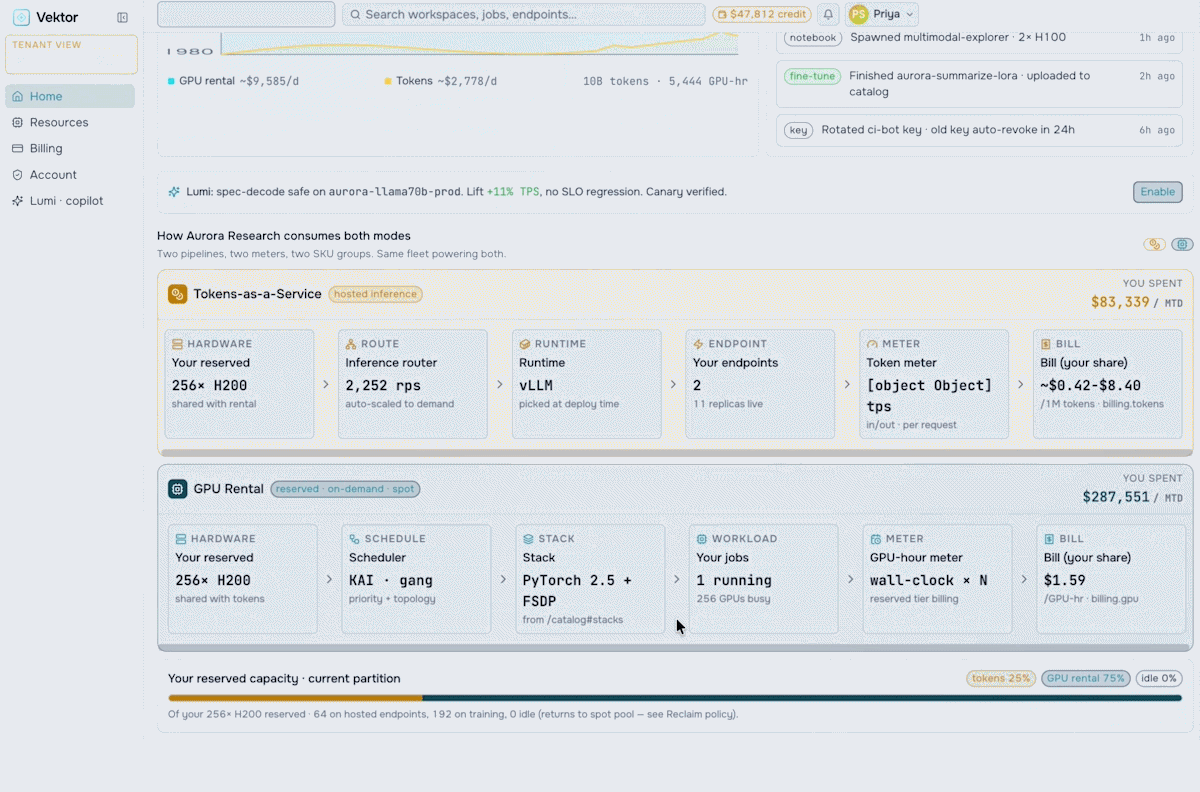
Gain real-time visibility into GPU utilization, token throughput, hybrid LLM spend, and cost-to-serve – all while delivering AI services securely, efficiently, and at scale.
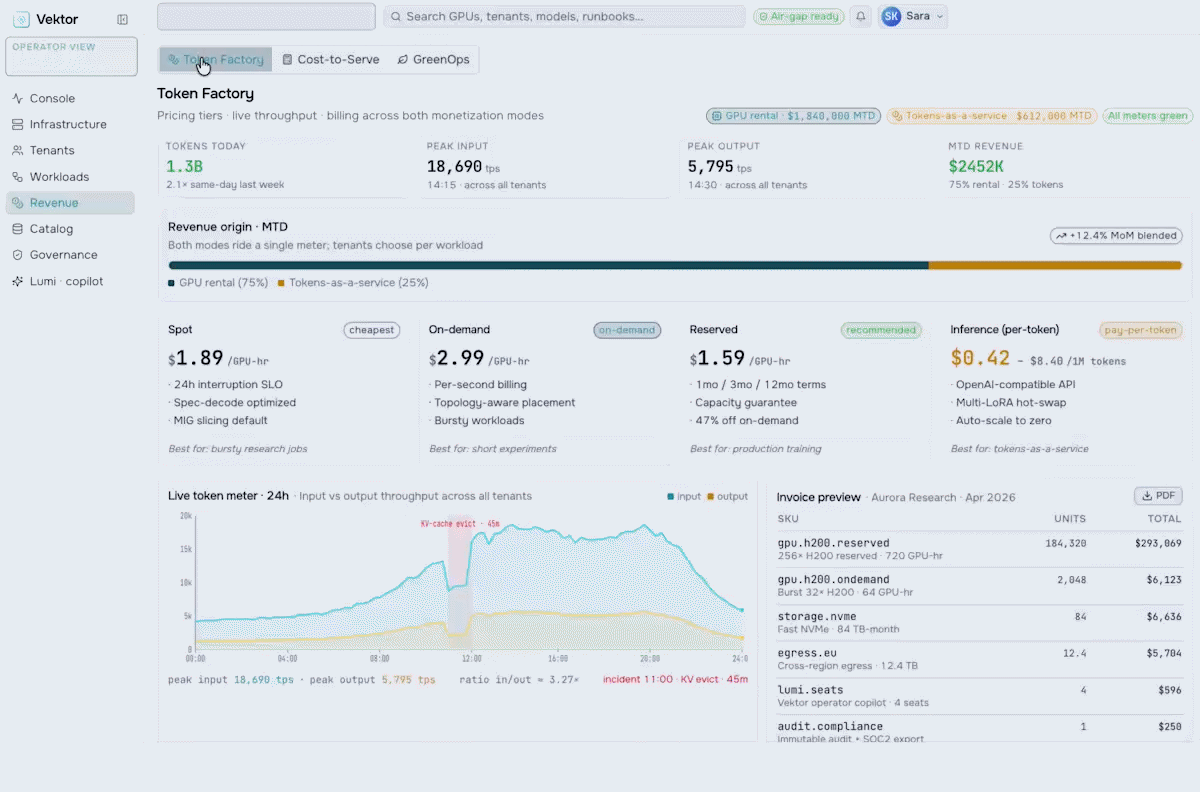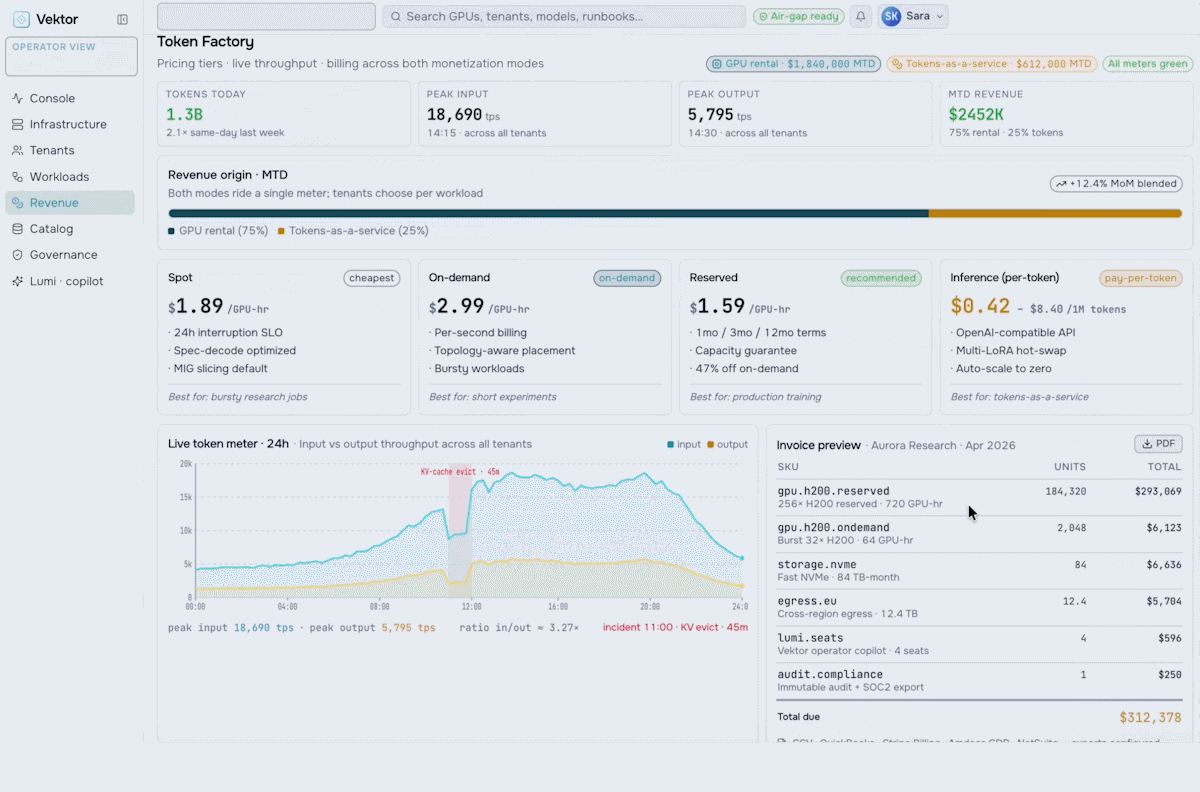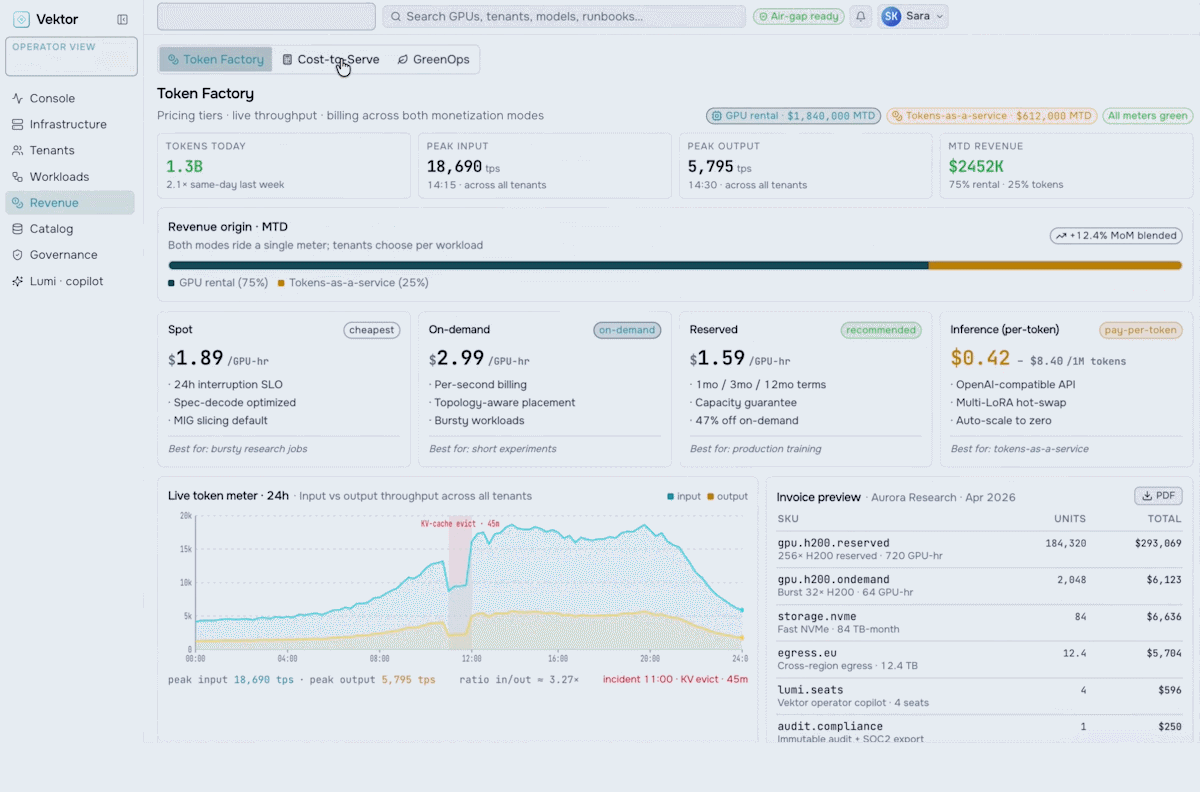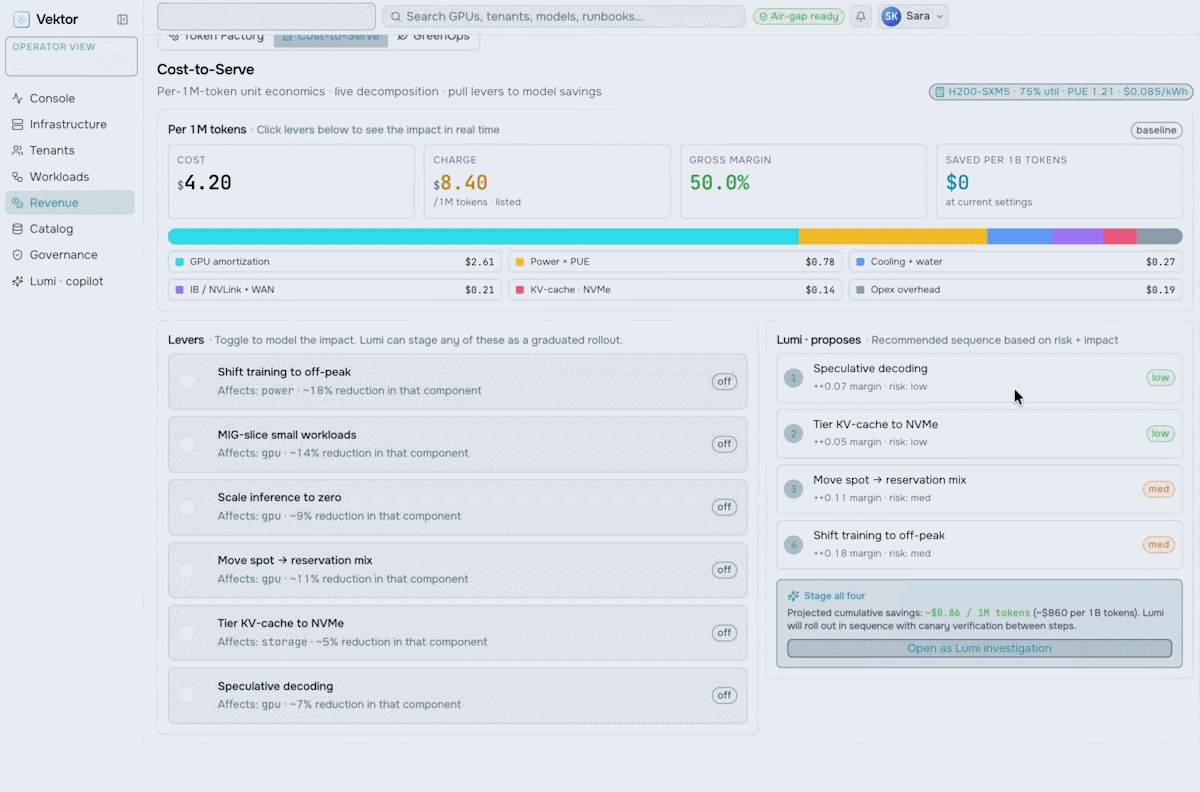
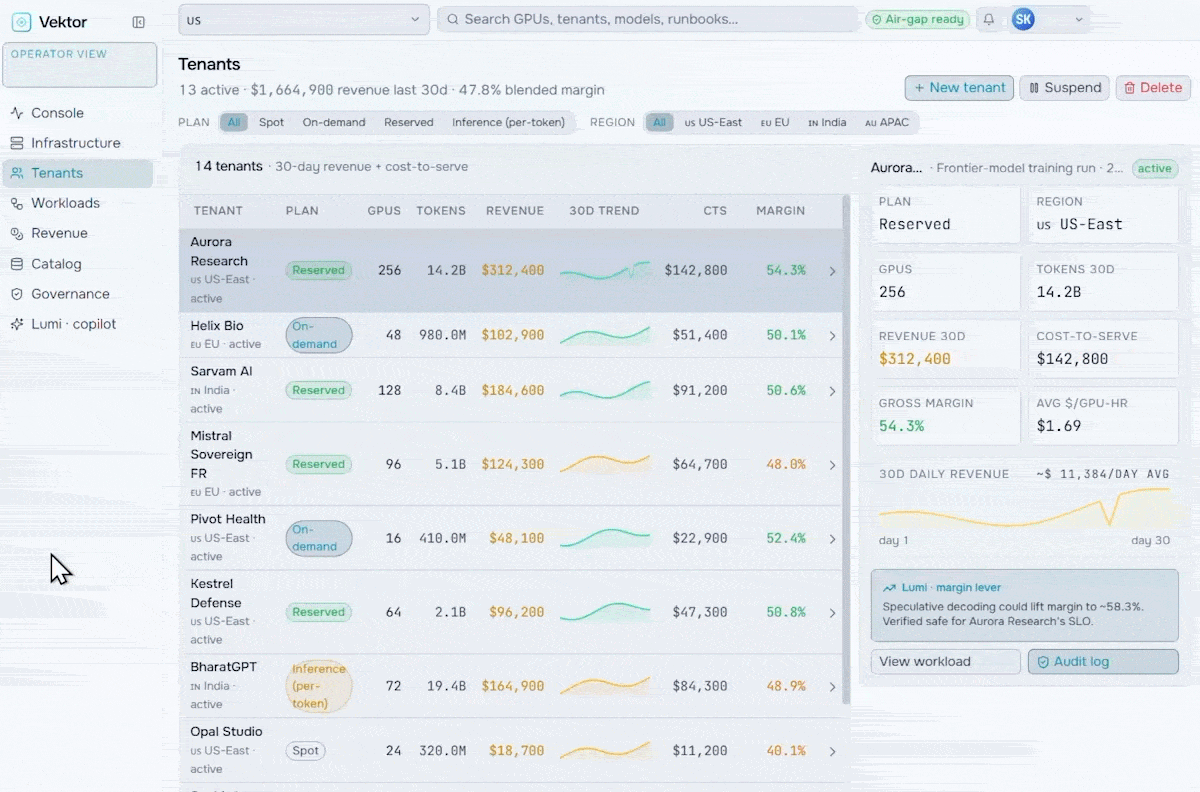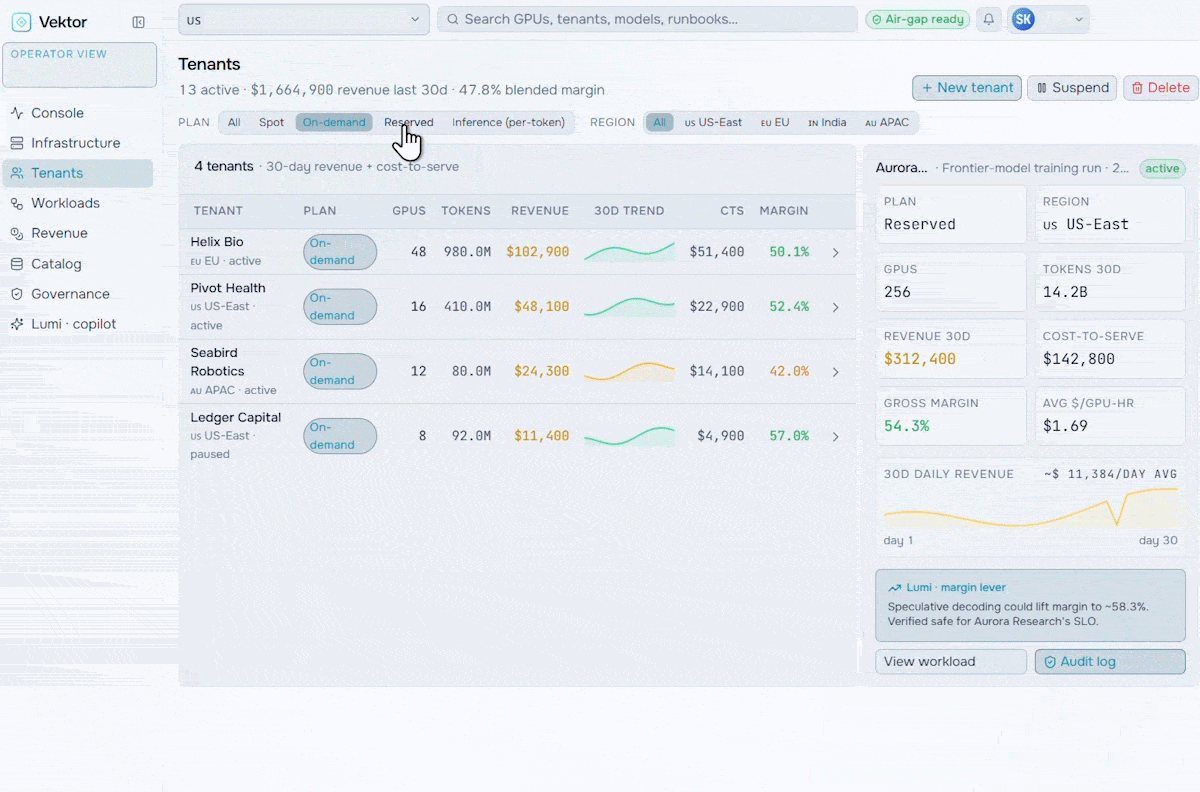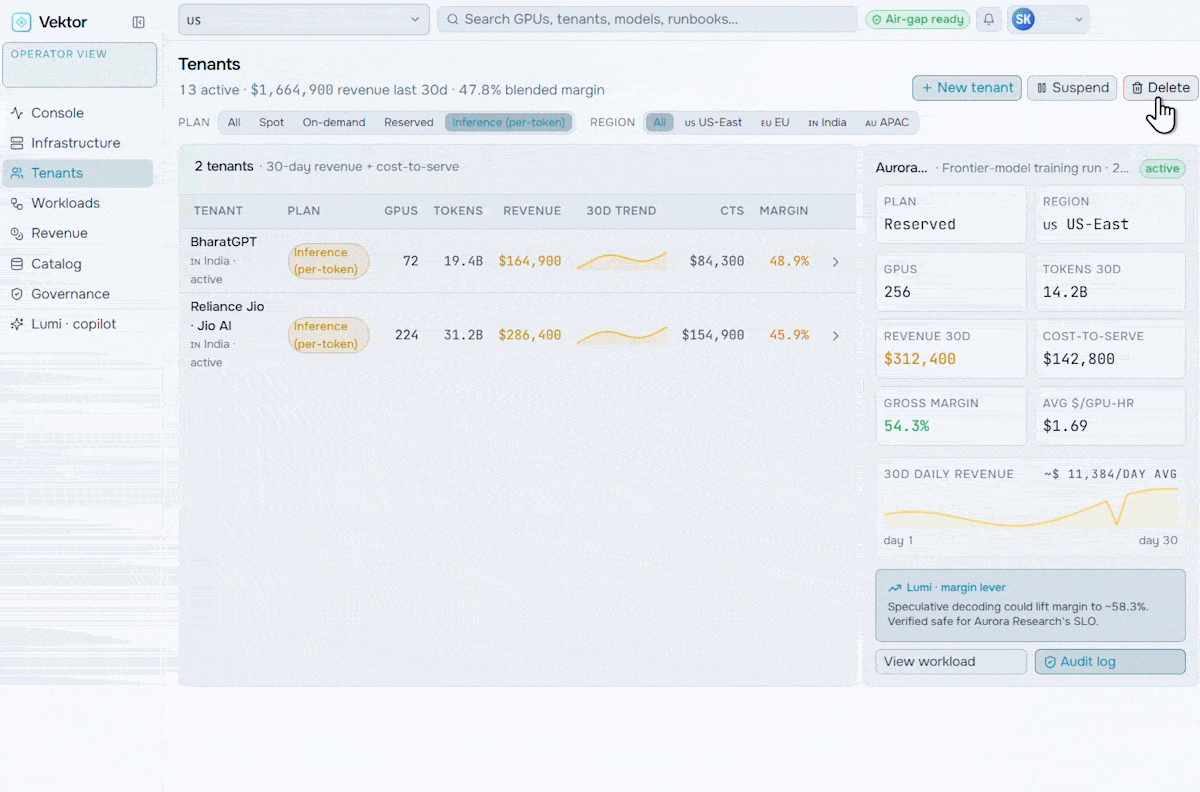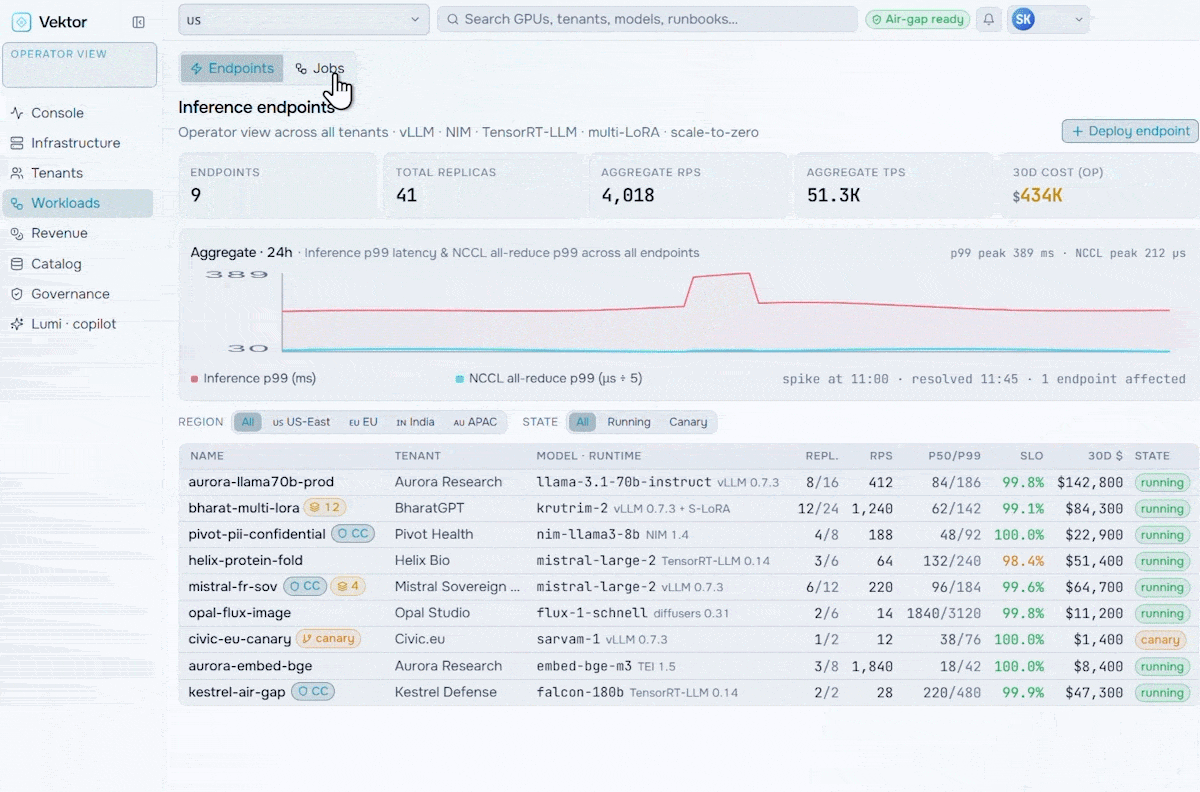
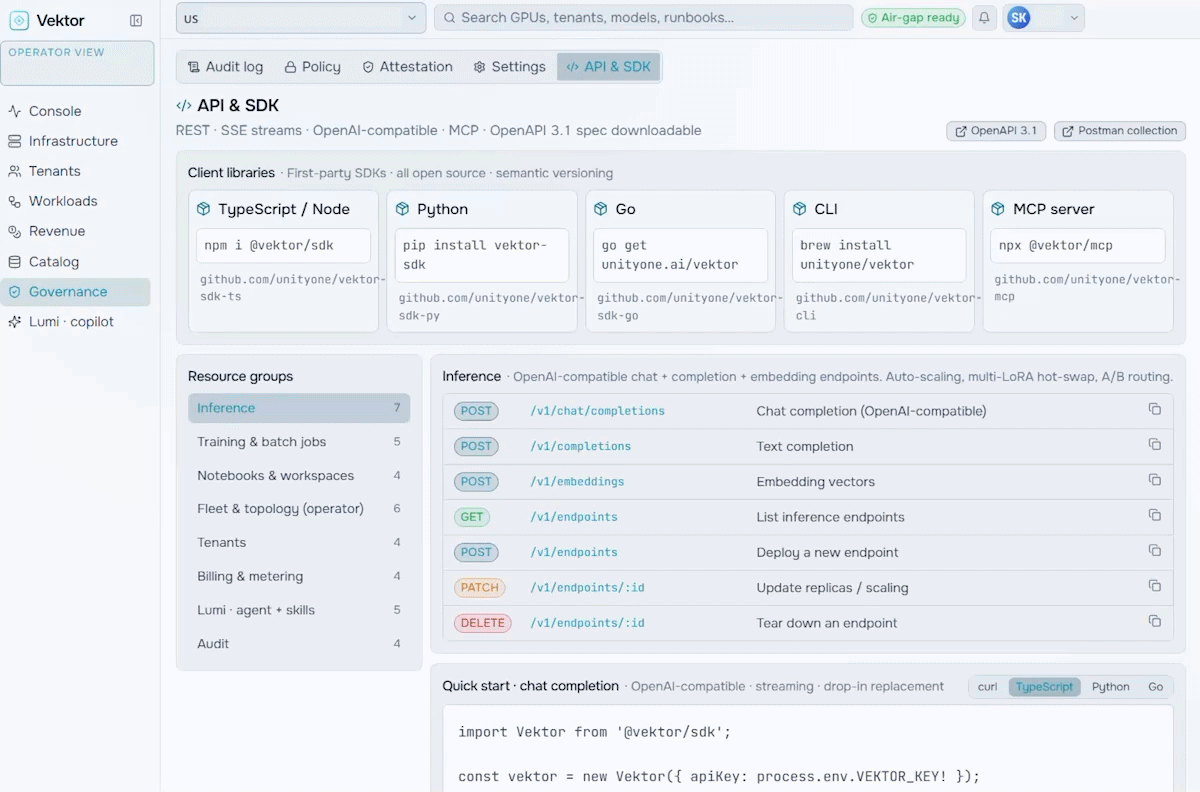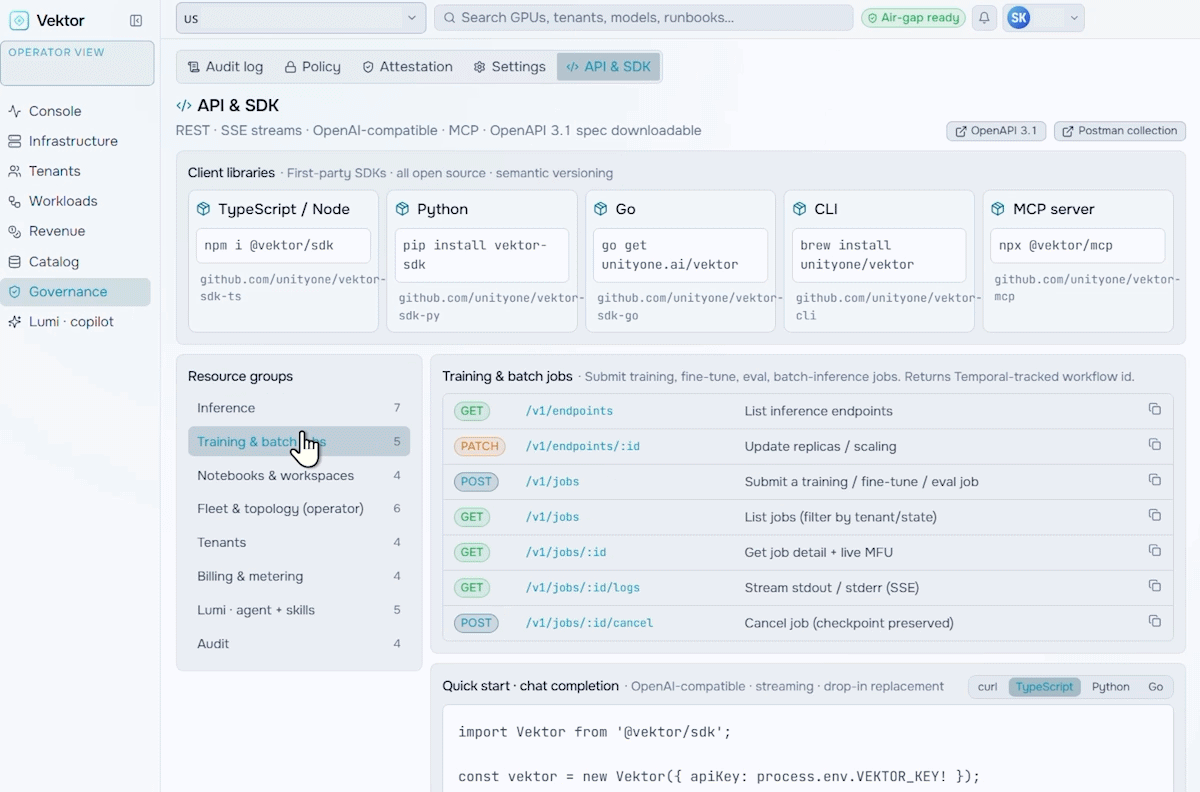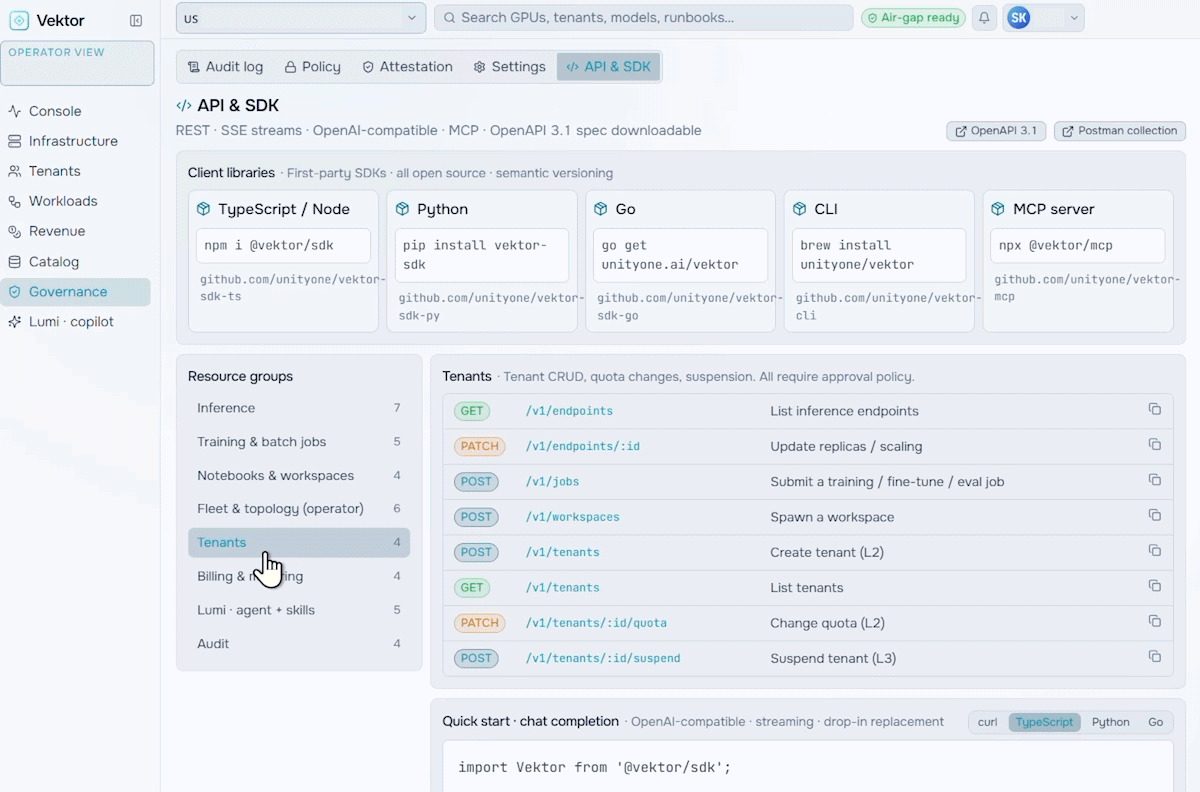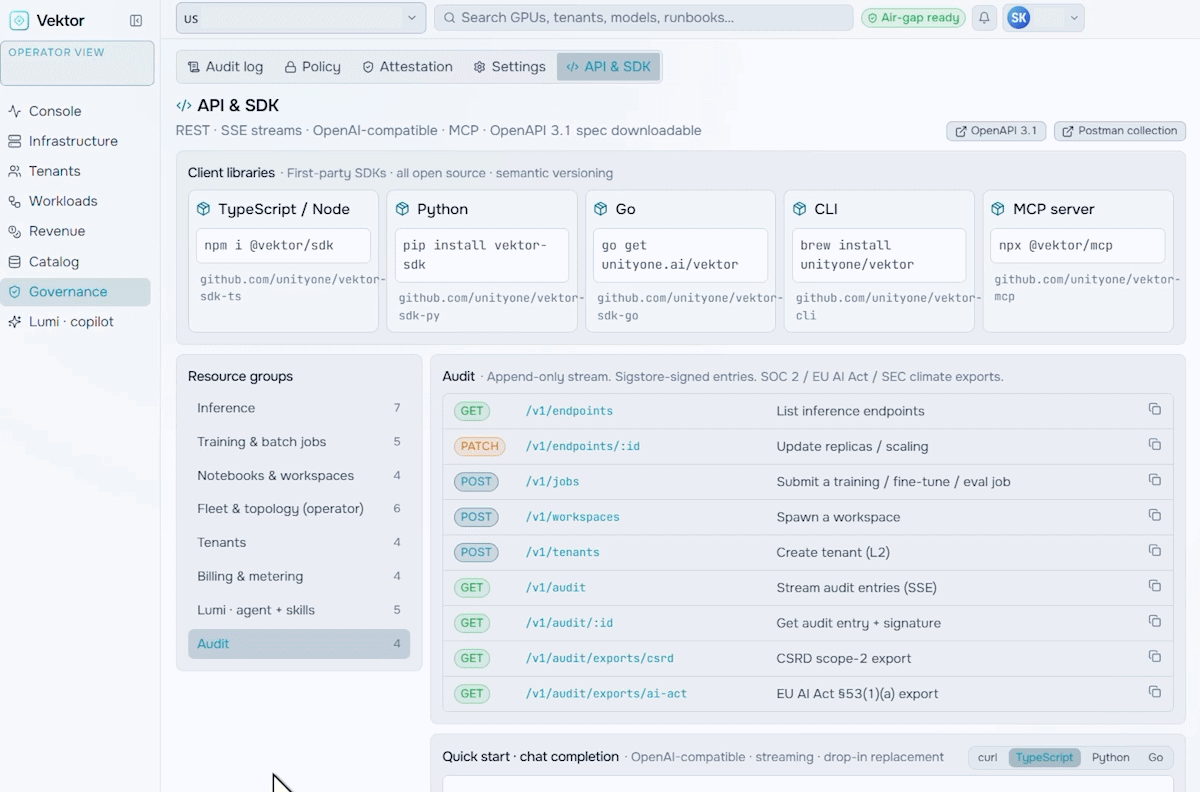
Revenue & Monetization
Scale from Infrastructure to Production-Ready AI
VEKTOR structures AI factory operations across four delivery stages, enabling operators to hand over a production-ready AI factory with complete client autonomy post-delivery.
Design
Plan your GPU fleet topology, define tenant architecture, configure switch fabric, and establish your service catalog and token pricing model before a single workload runs.
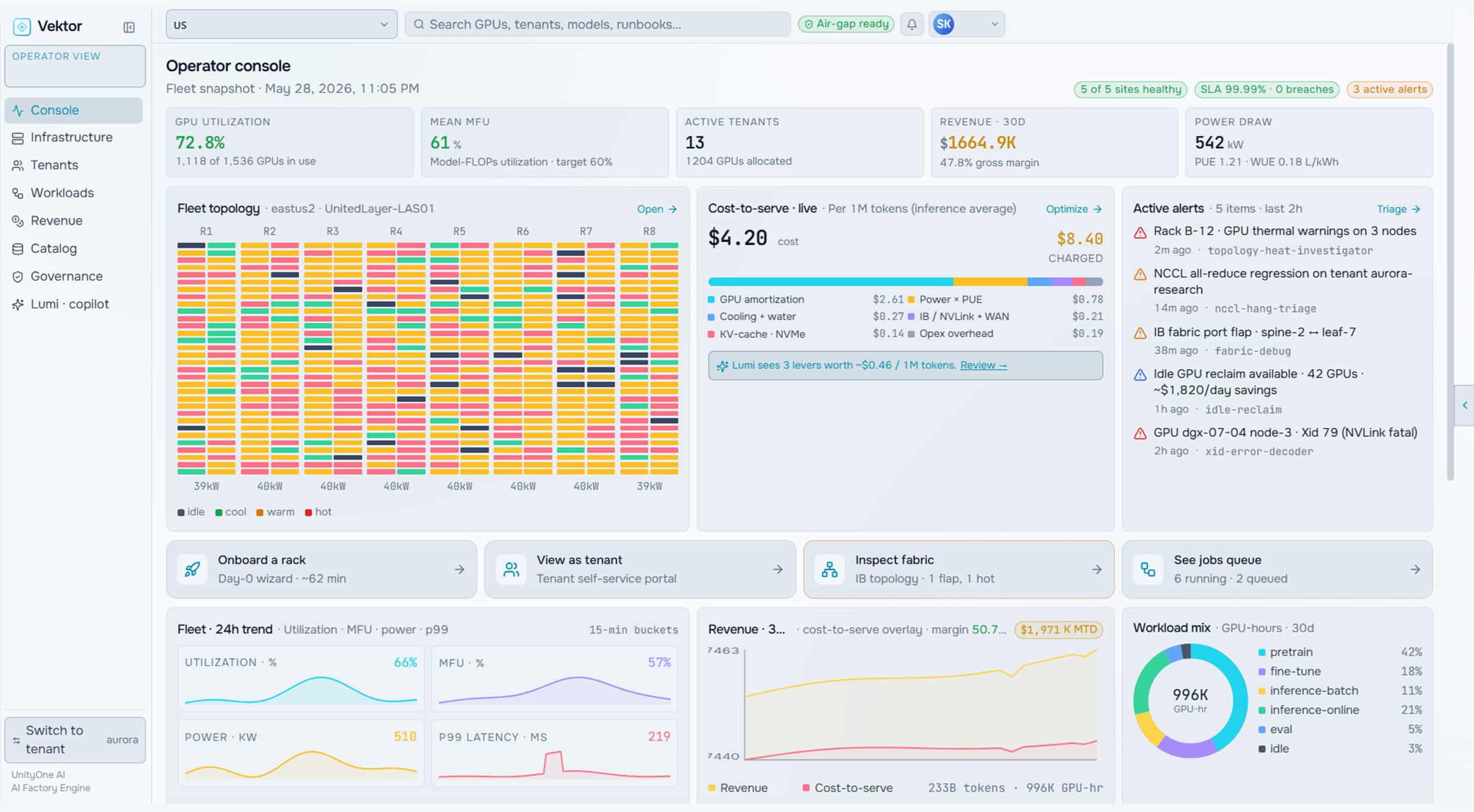
Build
Deploy and configure the full infrastructure stack. Onboard tenants, activate workload pipelines, connect public and private LLM APIs, and validate token flows.
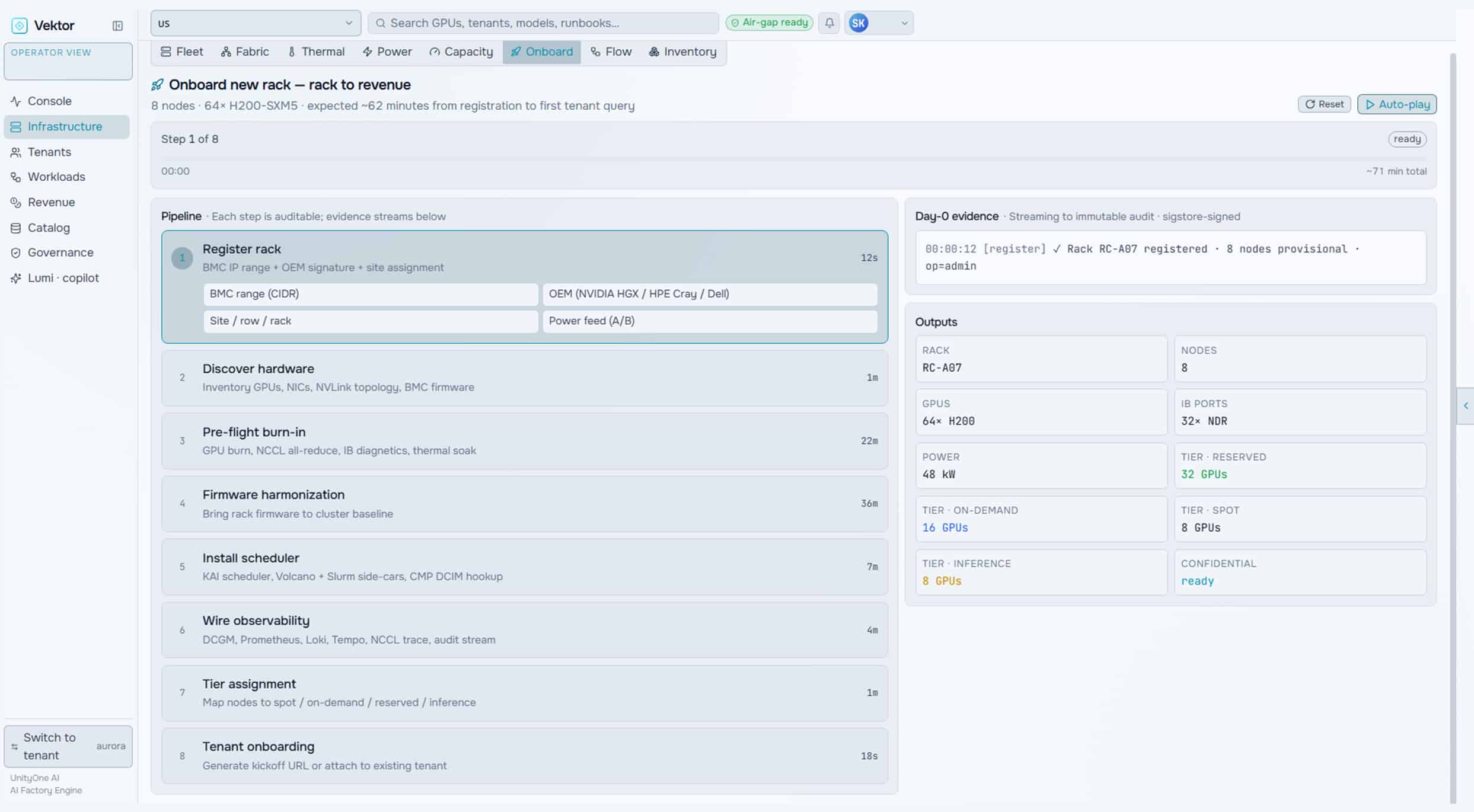
Operate
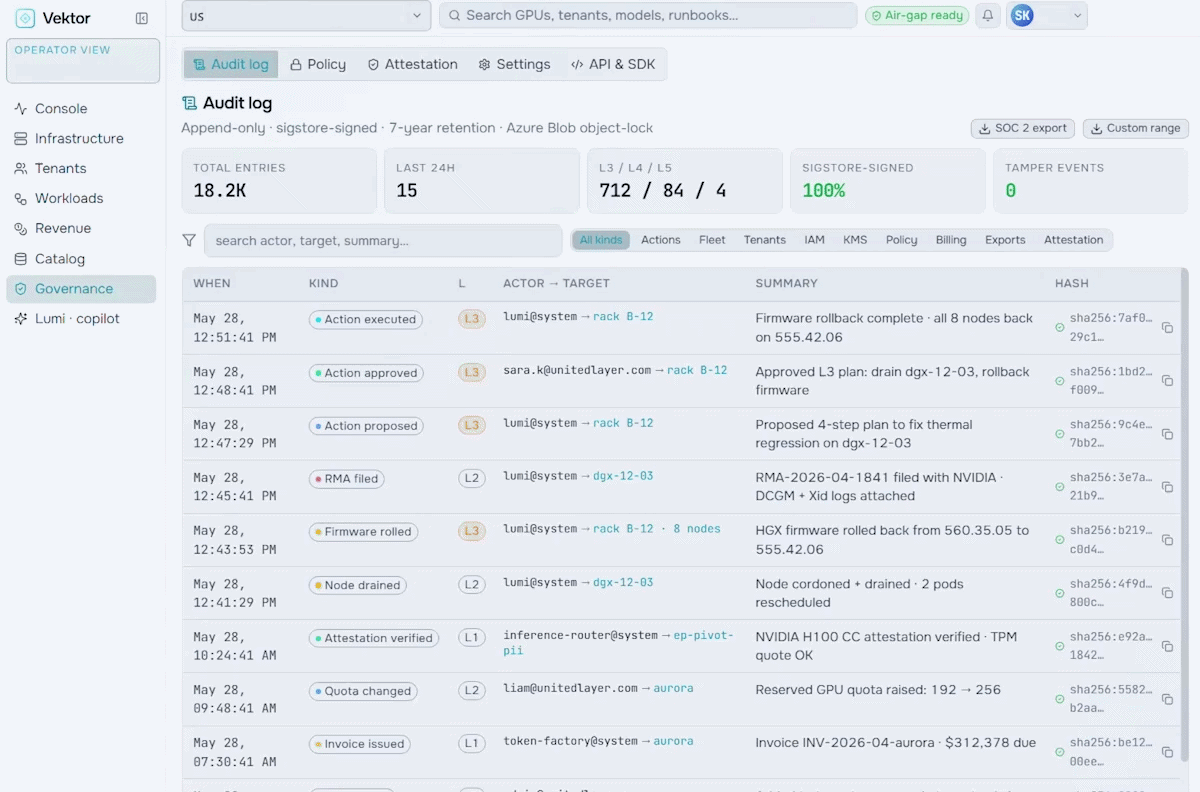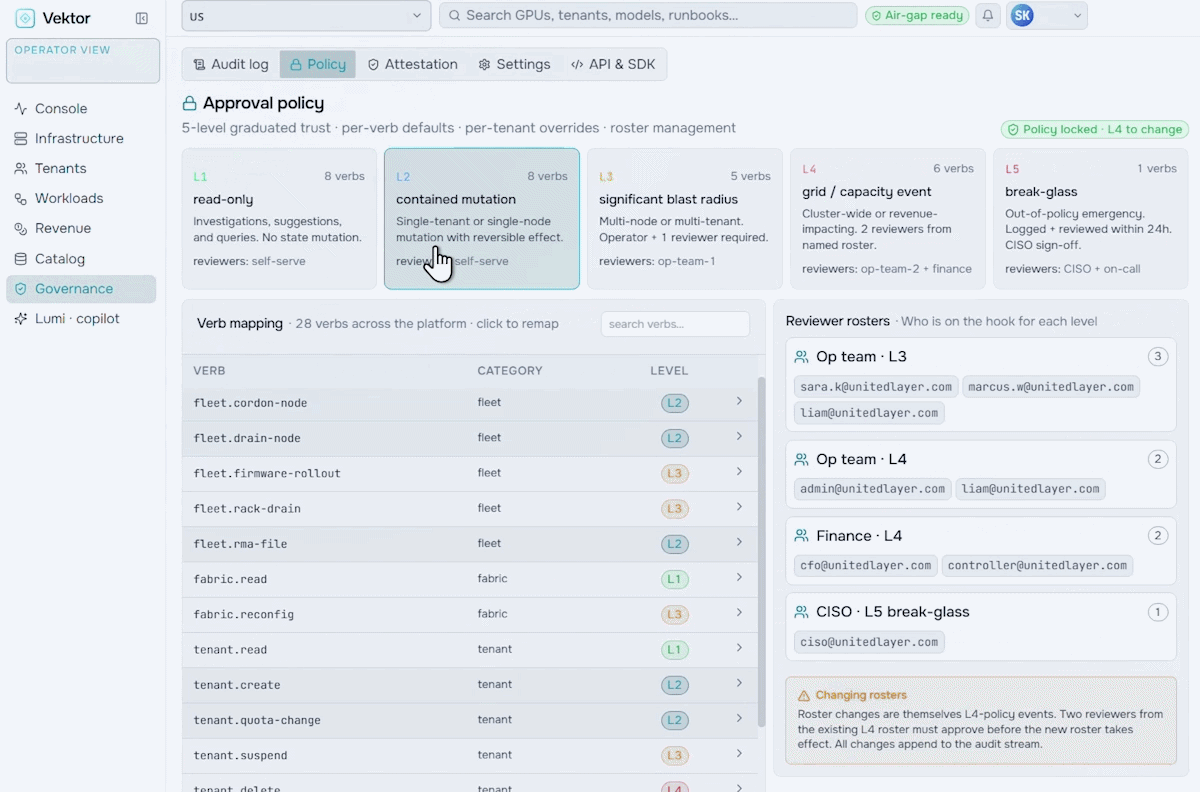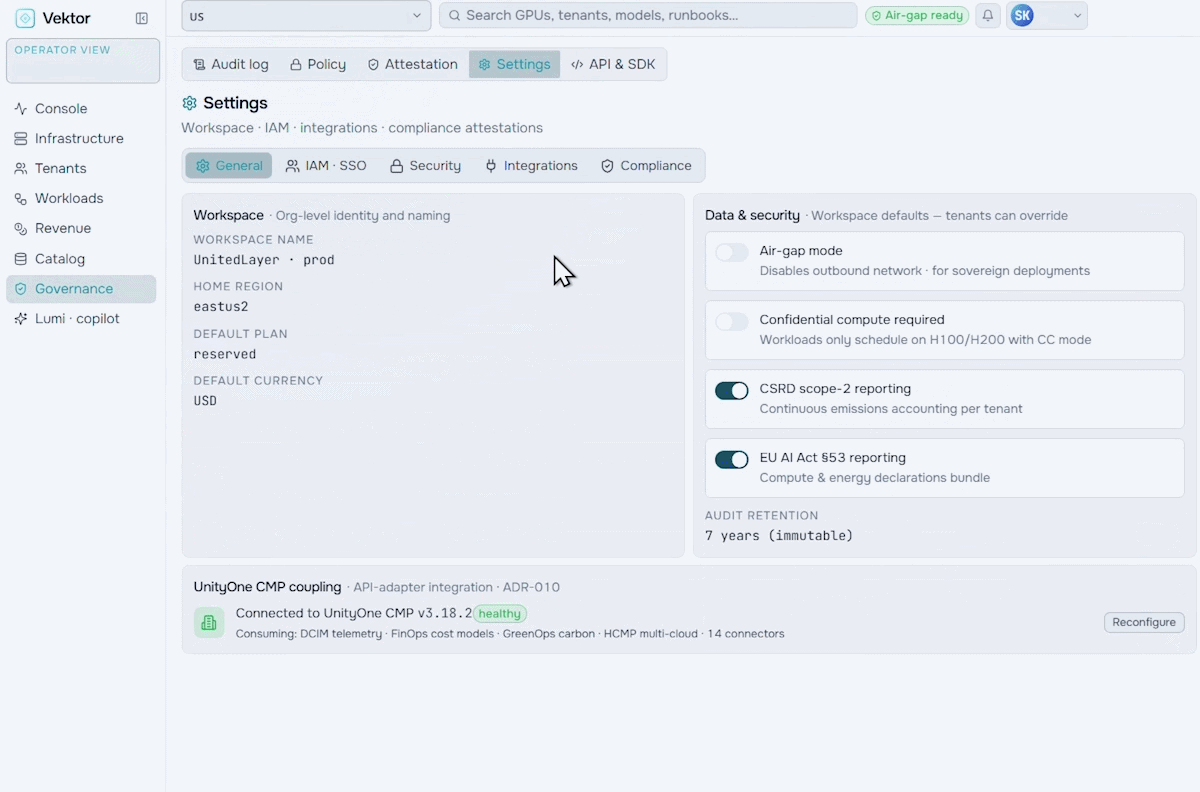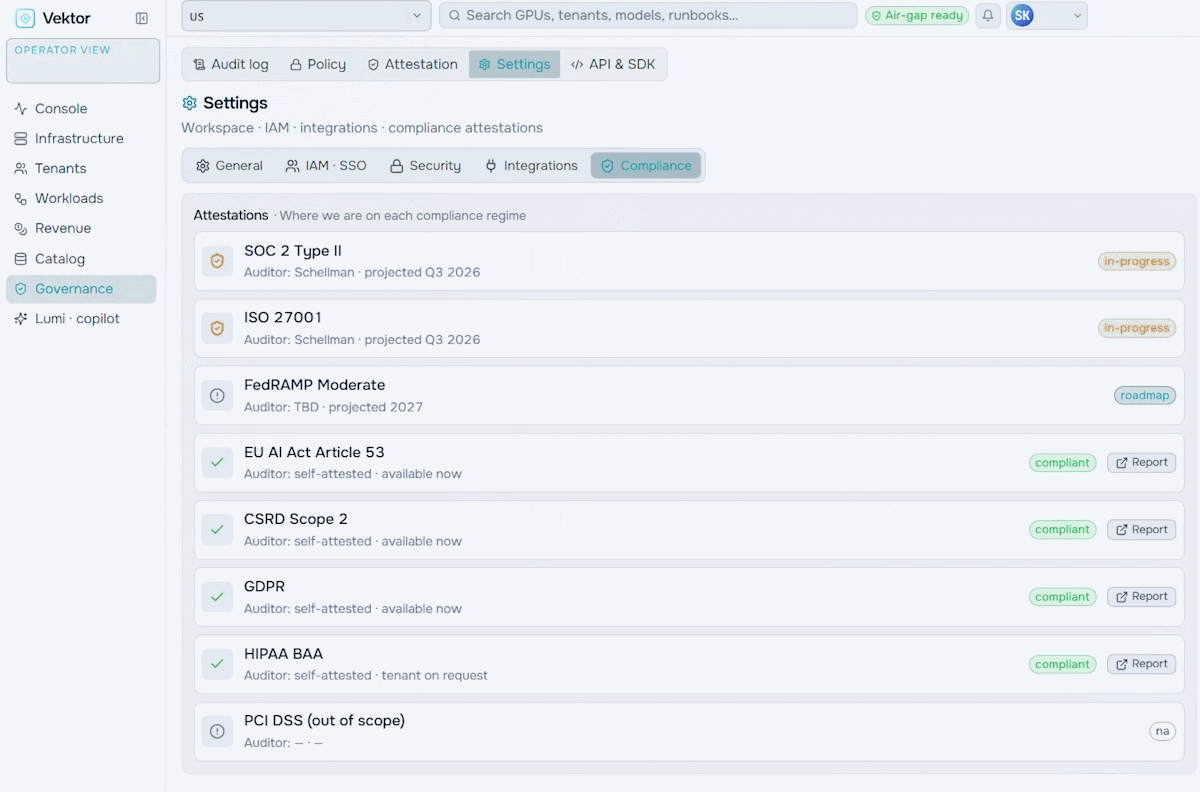
Run your AI factory in production. Monitor GPU health, manage token throughput, track revenue, optimize workloads, and enforce governance at scale.
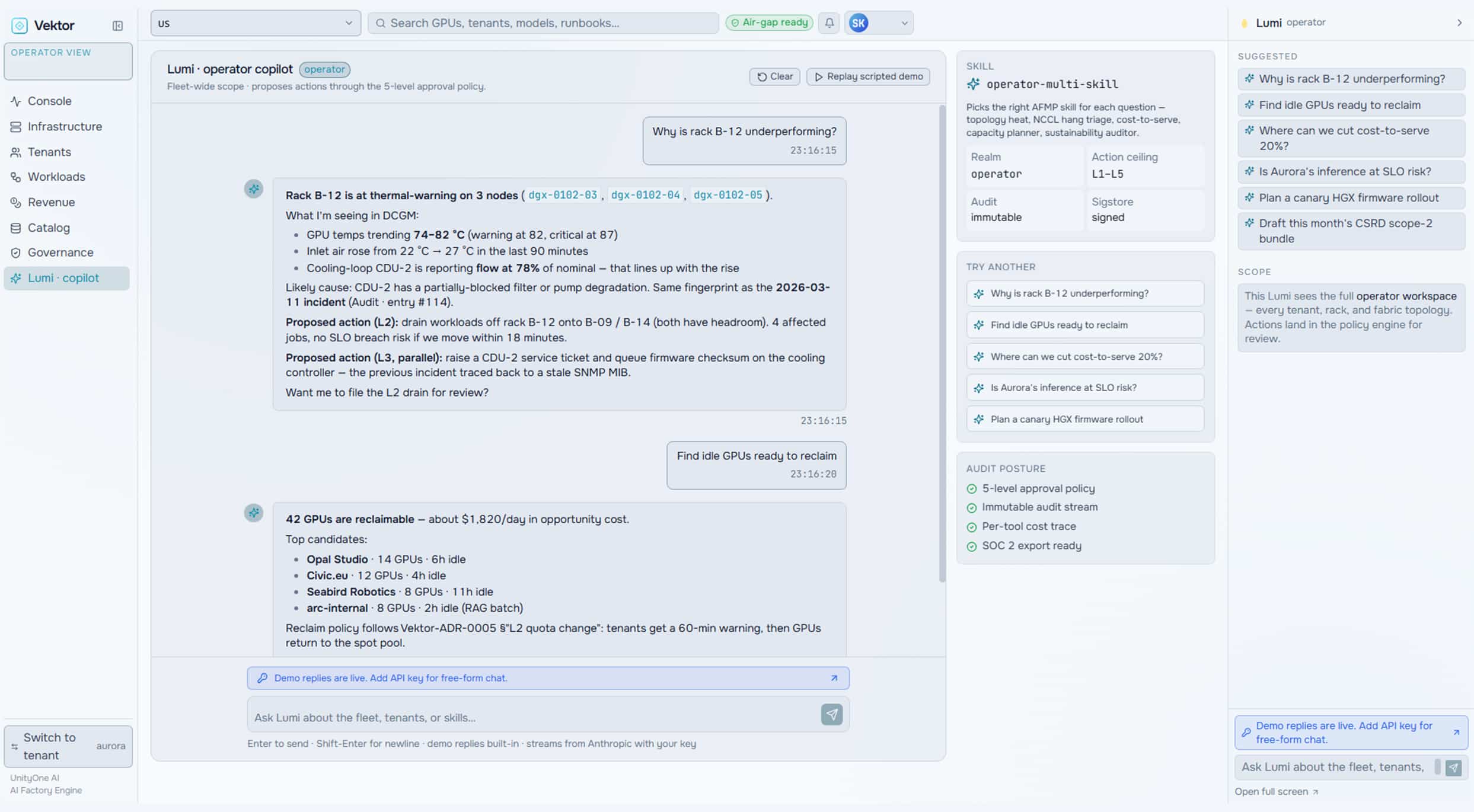
Monetize
Turn your AI factory into a revenue engine. Meter token usage per tenant, apply pricing and marketplace policies, run chargeback and showback, and track revenue against cost-to-serve.
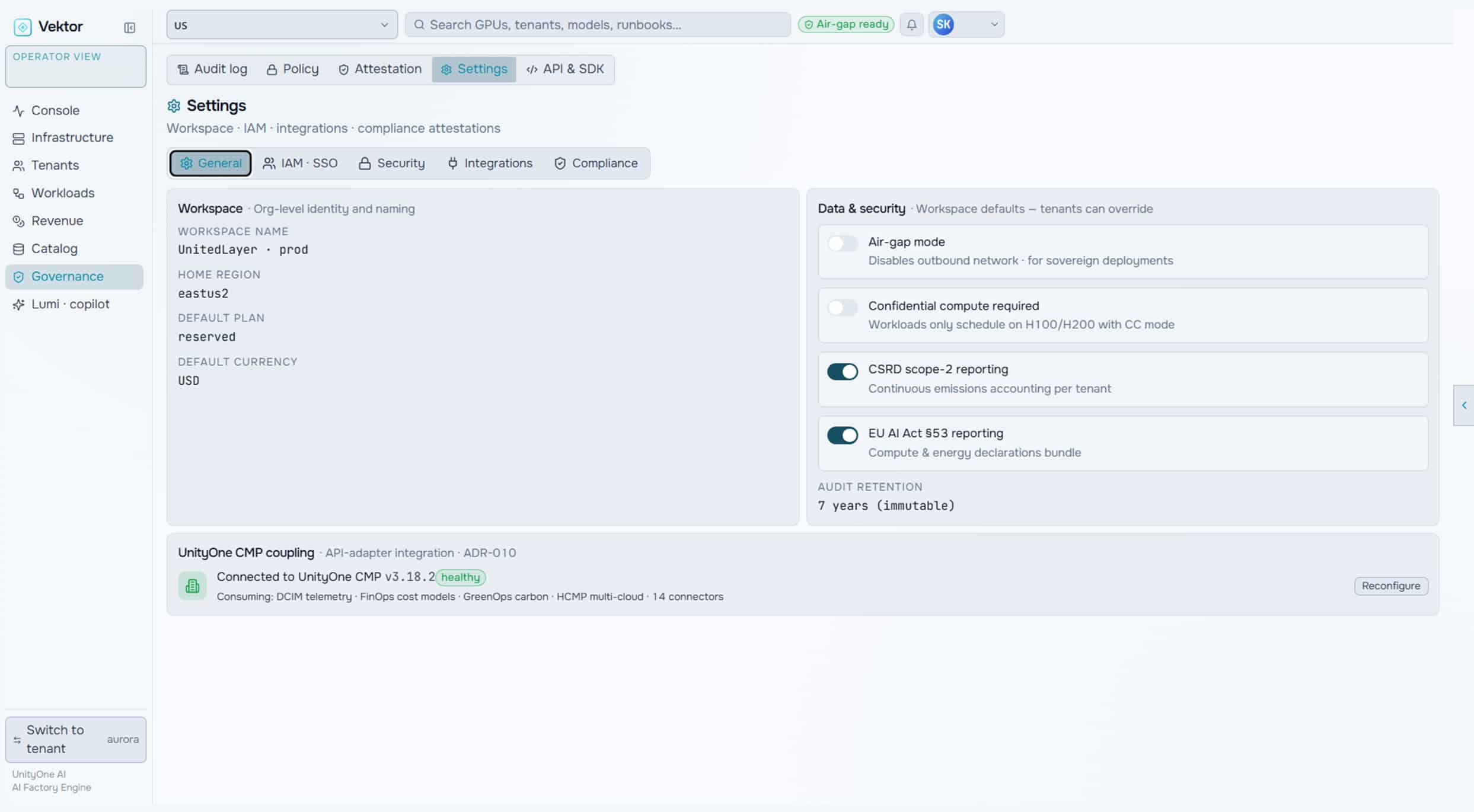
Use Cases
One Platform. Three Powerful Use Cases.
VEKTOR structures AI factory operations across four delivery stages, enabling operators to hand over a production-ready AI factory with complete client autonomy post-delivery.
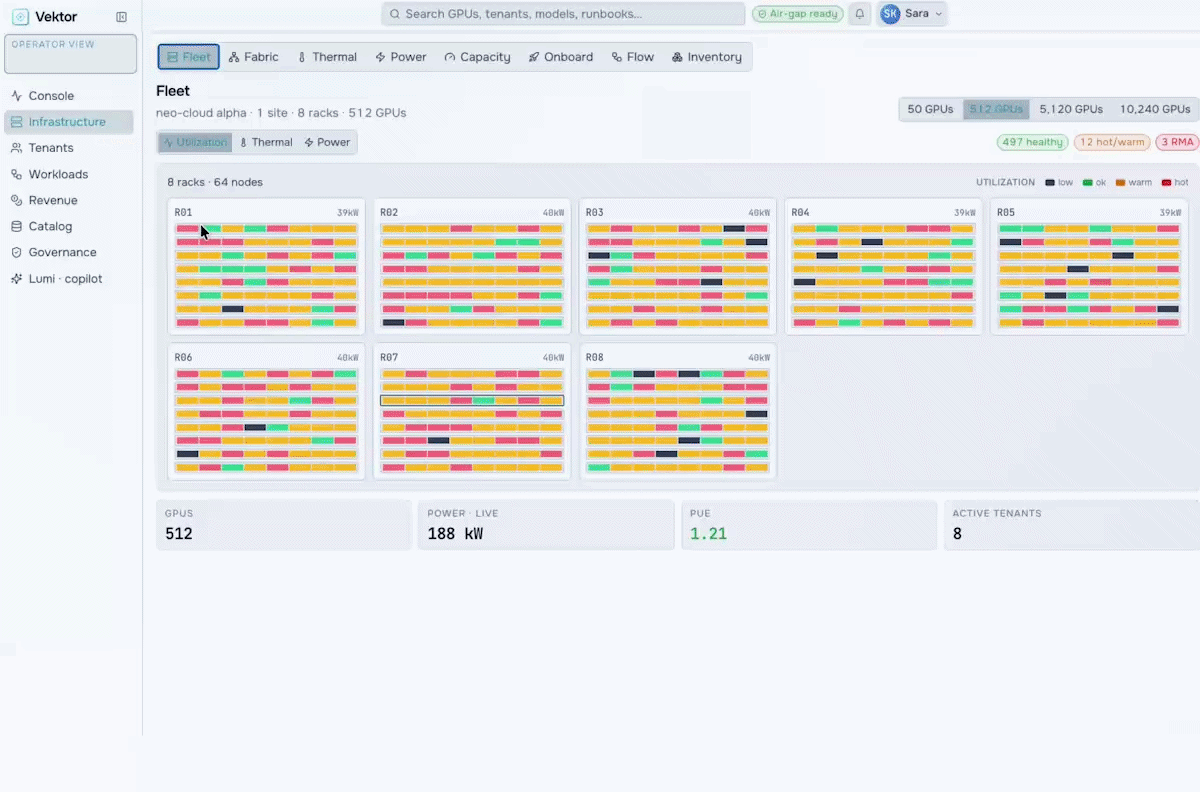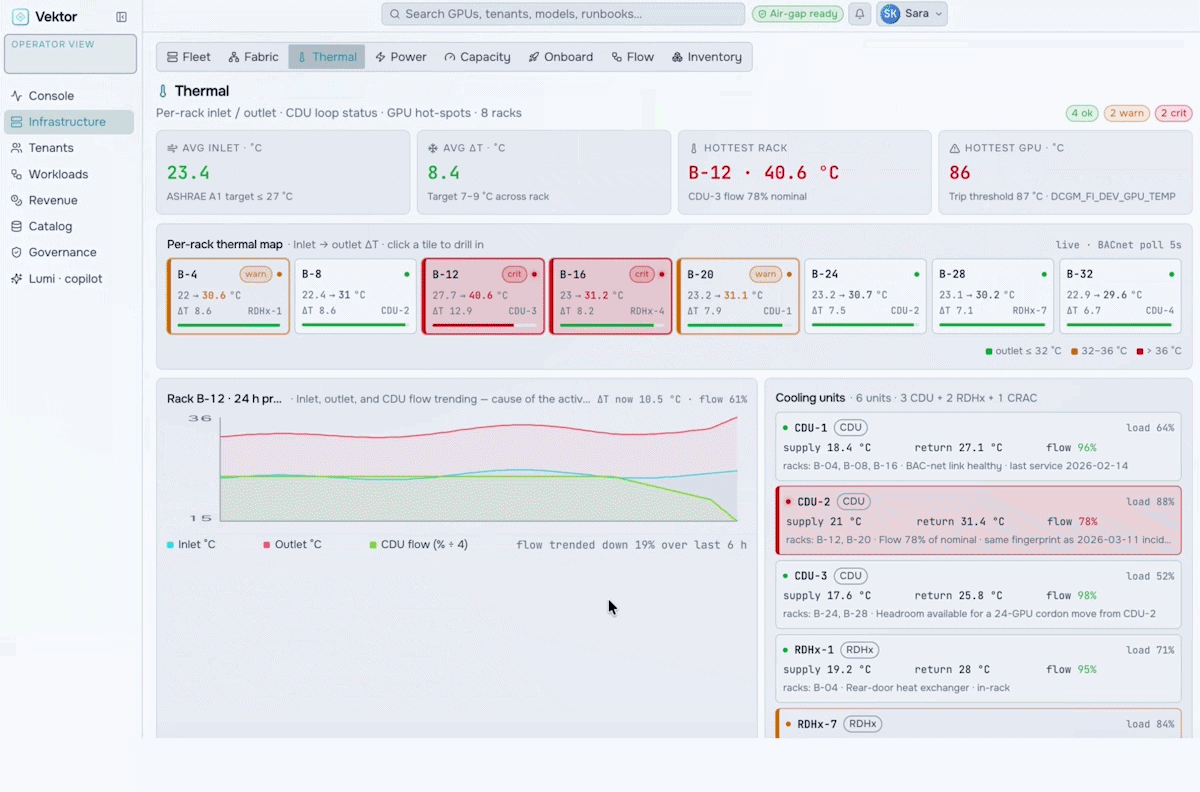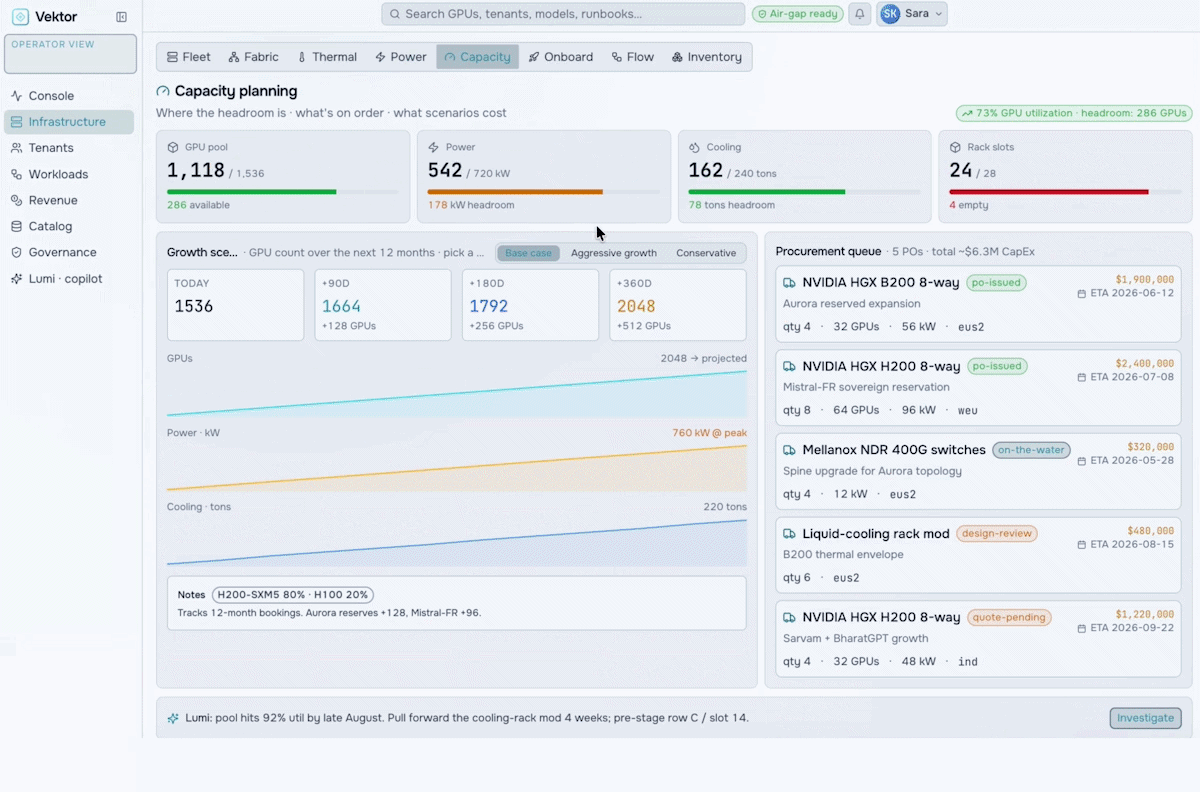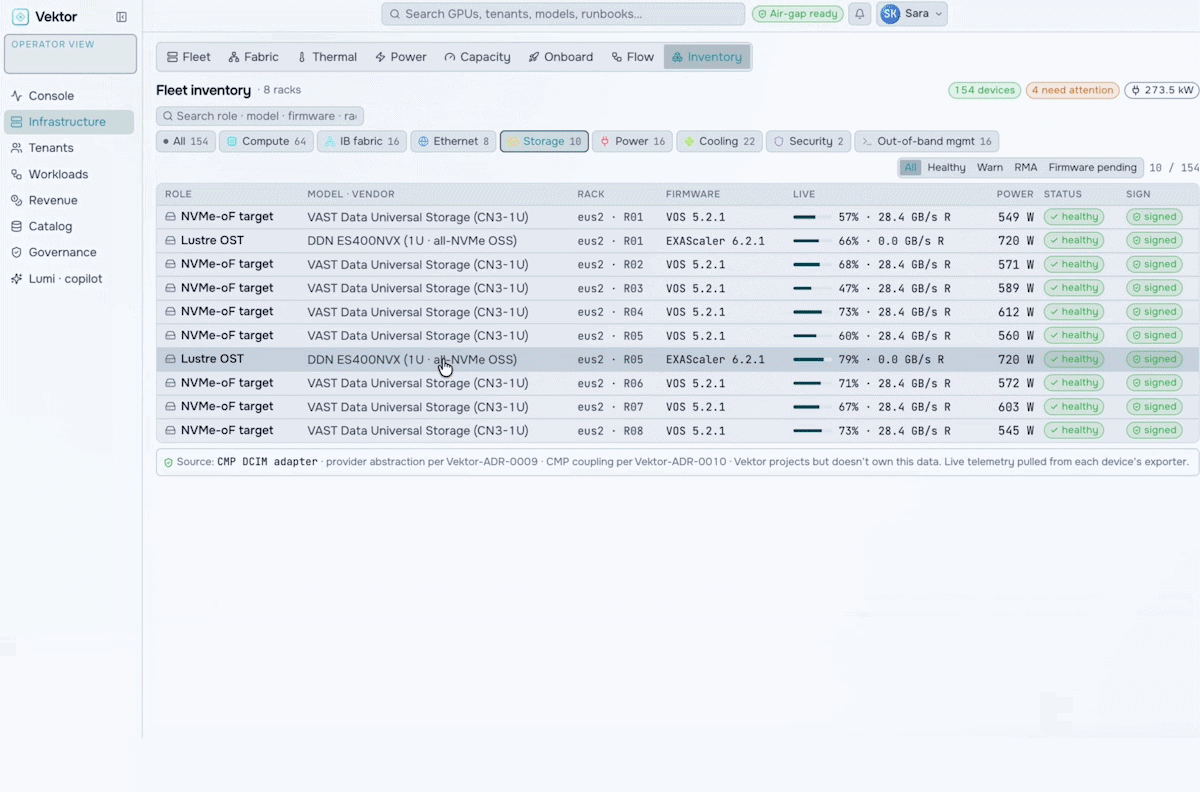
GPU Farm Management
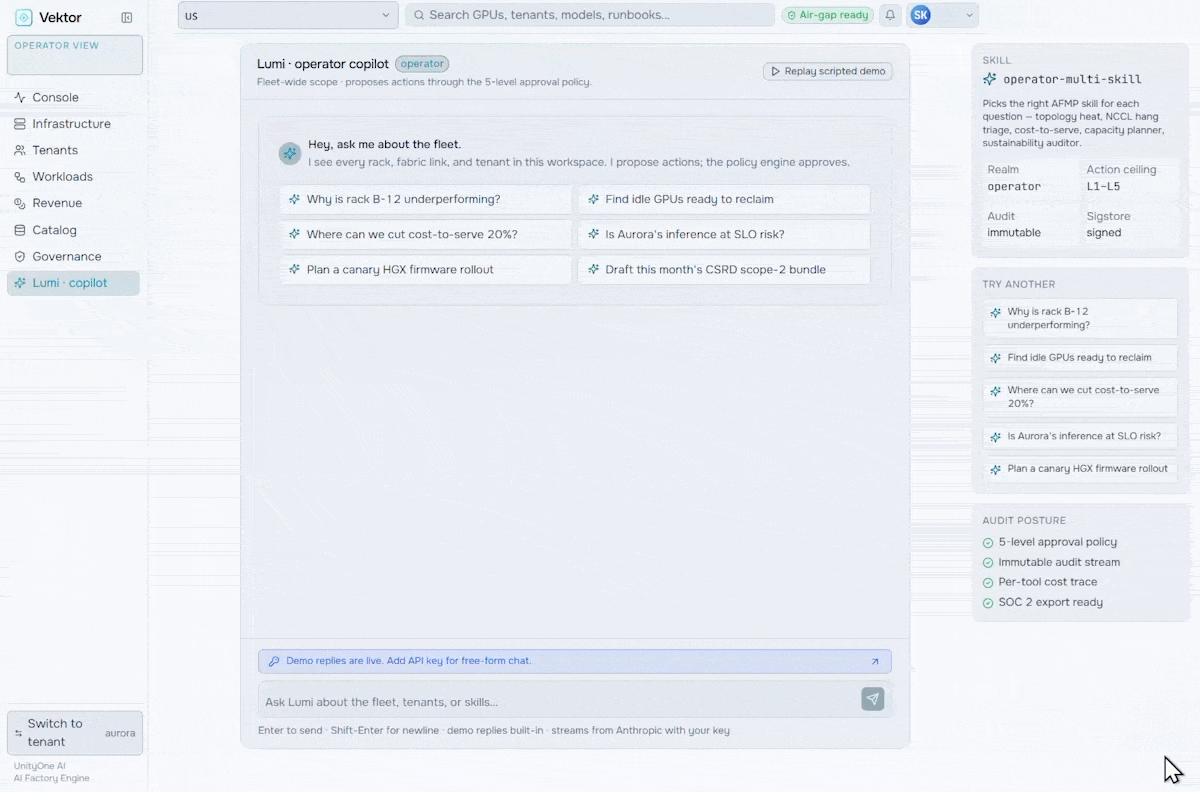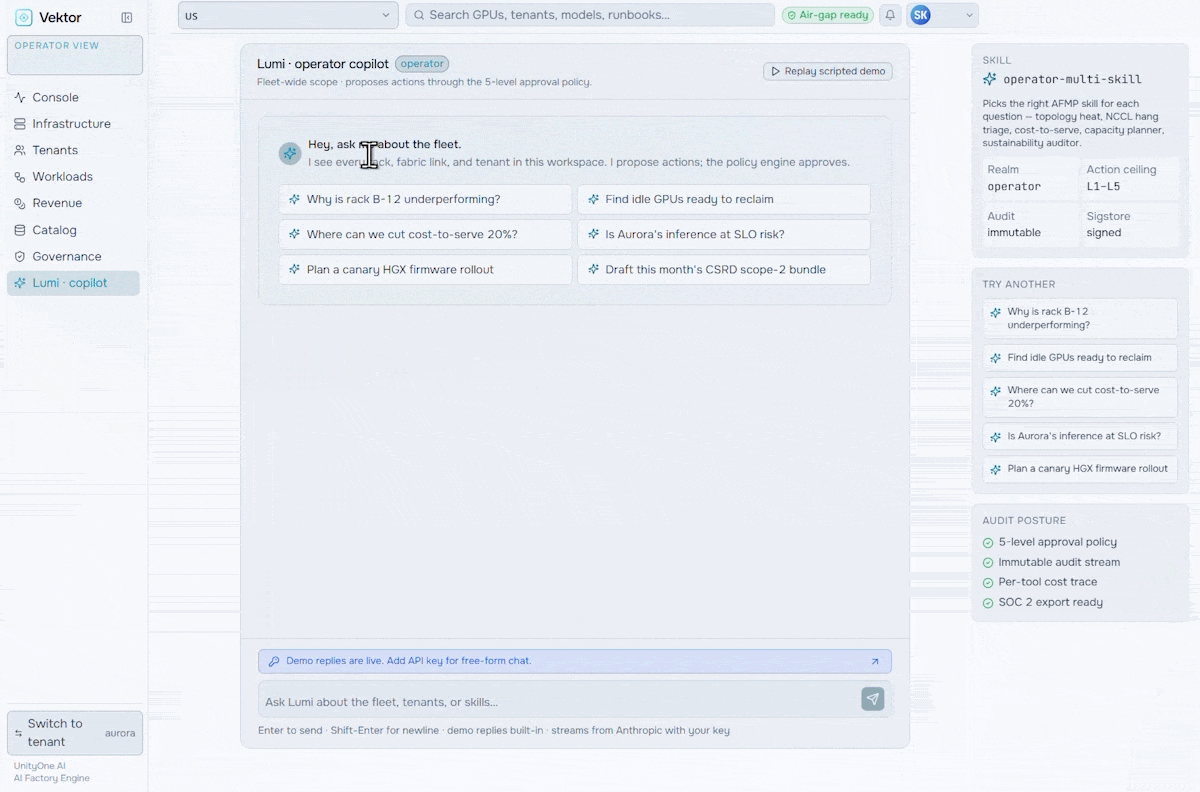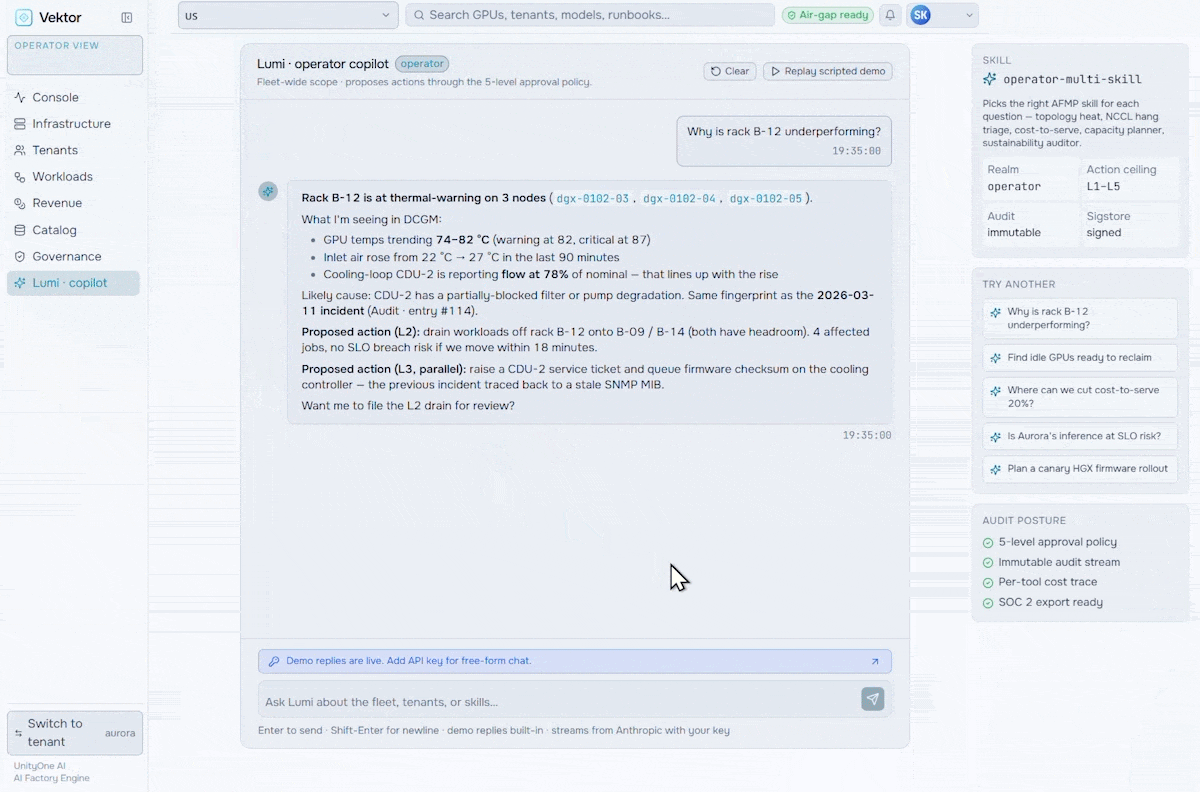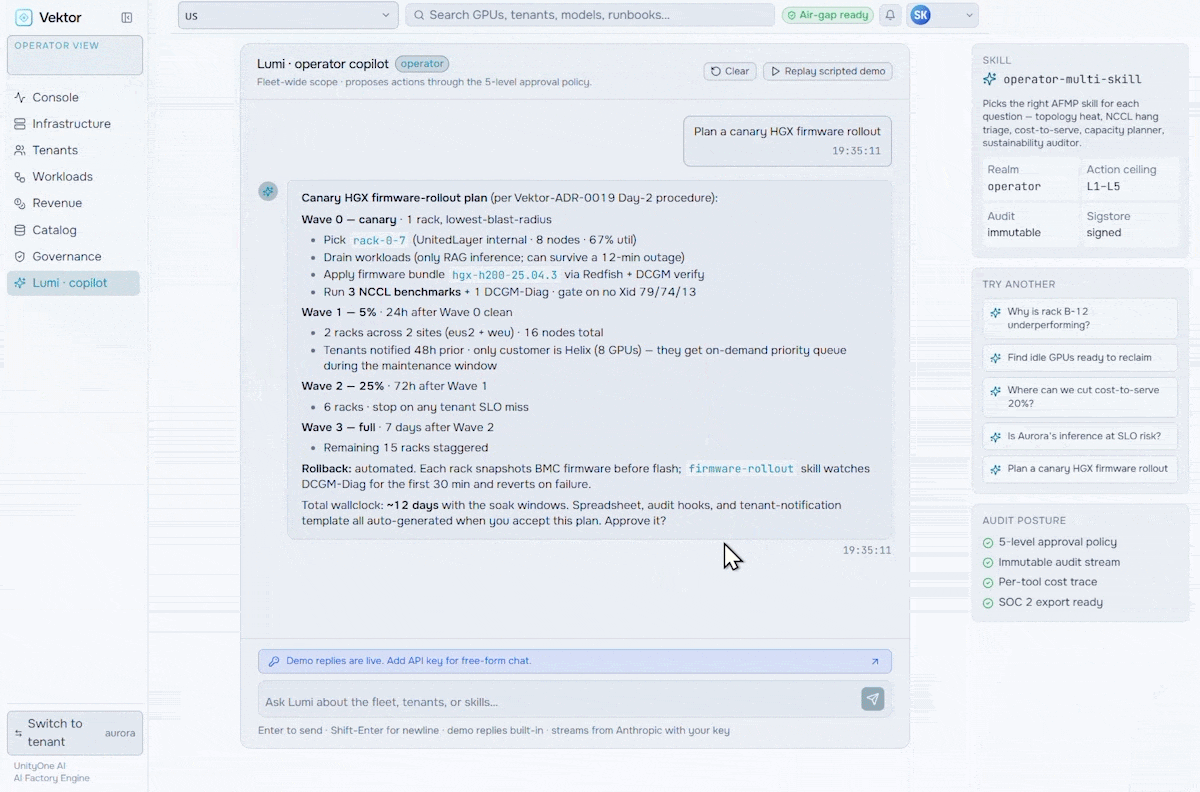
Manage, Govern & Optimize AI Factories
Orchestrate the future of enterprise intelligence with governed AI factory operations. Purpose-built to manage, govern, and optimize AI factories, VEKTOR enables organizations to deploy private AI stacks quickly, accurately, and at lower cost.


Ready to Build Your AI Factory?
Run your GPU fleet, govern your tokens, and know your exact cost-to-serve — from design to handover, on one operator console.
")
")